Are you sure Intersect is the right tool for the job?
UPDATE
ArcGIS Pro 1.0 introduced a PairwiseIntersect tool which emulates the pairwise tool discussed in this blog post.
ArcGIS Pro 1.1 has an additional pairwise tool, Pairwise Dissolve.
By default, starting in ArcGIS Pro 1.1, both the PairwiseIntersect and PairwiseDissolve tools run in parallel mode. This will allow these tools to distribute the work to all (or a portion of) the logical cores on the machine. The performance benefit of parallel processing varies from tool to tool and depends on the input data being processed.
Please see the following for more info: PairwiseIntersect and PairwiseDissolve
(Note: There are no system Pairwise tools provided in 10.x. Continue to use the provided methodology and scripts included with this post.)
=========================================================
I often talk with people using ArcGIS Geoprocessing who find themselves surprised about the amount of time the Intersect tool takes to run, or confused about the output results. Much of the time this confusion comes from a misperception about what tool to use for the analysis, or from a lack of understanding of what the Intersect tool does.
Here’s an example… A user contacted me about the Intersect tool because the tool would run for hours and then fail. They perceived their data as small and really thought Intersect would only take a few minutes.
My first question, and one you should ask too is, “What do you really want for a result?”
The answer in this, and many cases was “I want to know how much of each feature in input 1 is in each feature in input 2.”
Cool! That means Intersect is not the right tool to use!
Intersect does not compare each feature in the first input to each feature in the second input. It works in a much more complex, thorough way. The intersect tool is for creating a topologically correct fabric across the entire extent of the dataset and return those newly created features that were created due to overlap from a feature in each input. The Intersect tool throws all the features from all the inputs into one bucket, and passes this to the underlying topology engine so it can create this topological fabric. This means all relationships, between all features, including those relationships within each input are determined and new features are created for every interaction. The Intersect tool then selects just those features from this topologically correct fabric.
So, for the Intersect tool if you have 2 inputs the output will only contain those features that were created where a feature from each of the 2 inputs overlapped. If you have 100 inputs the output will only contain those features that were created where a feature from each of the 100 inputs overlapped.
Here is what looks like a very simple example of intersecting one polygon layer with 10 overlapping polygons with a single polygon from a second feature class (features are labeled with their OID):
Input 1 (10 input polys that overlap)
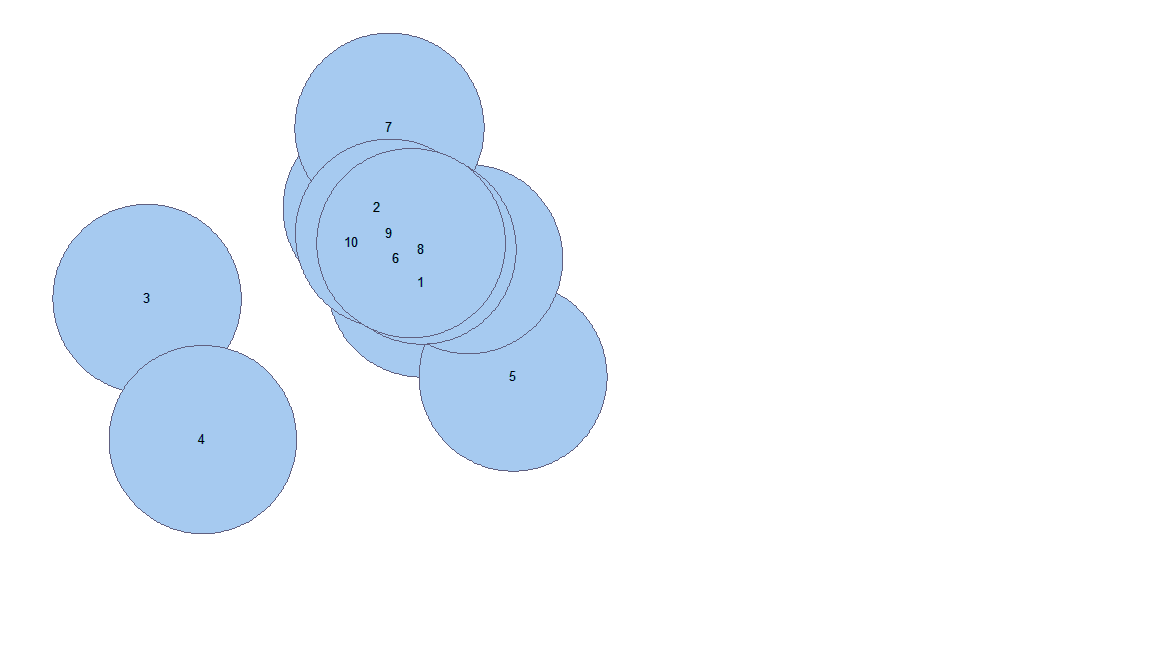
Input2 (One polygon)

Intersect output will contain new features created from the intersection of the overlapping polygons in Input1 and their intersection with the polygon in Input2:

As you can see, there are now a lot more polygons in the output (167!) than there were in the inputs combined. Imagine if Input1 was actually complex:

Ouch!
Using the output of Intersect you now have to perform further analysis to put together polygons that were broken apart in Input1 due to their intersections with one another. Seems like a lot of work to figure out how much of the polygon with OID 9 in Input1 intersects with the polygon in Input2 right?
So what should they, and you, be doing if you want to know how much of each input feature intersects with each feature in the second input? Here are two possible workflows, one good, and one much better, that will give you exactly what you want, and may get you the results of your analysis much faster.
Good… Clip and Transfer Attributes workflow
This is a simple approach that uses existing tools and can be setup by anyone familiar with scripting. The only ‘advanced’ part, is the use of a cursor, but it should be fairly easy to understand.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import arcpy, os, sys, timearcpy.env.workspace = os.getcwd()arcpy.MakeFeatureLayer_management(r"Data.gdb\input1","input1")arcpy.MakeFeatureLayer_management(r"Data.gdb\input2","input2")arcpy.env.overwriteOutput = Truearcpy.CreateFileGDB_management(os.getcwd(),"output.gdb")try: #For each input2 feature in the poly feature class, select it, select the input1 features that intersect it, then clip it with the selected input2 feature input2Count = int(arcpy.GetCount_management('input2')[0]) progressCounter = 1 startTime = time.time() with arcpy.da.SearchCursor("input2", "ID") as cursor: for row in cursor: print "\n\ninput2 # " + str(progressCounter) + " of " + str(input2Count) print "Processing ID = " + str(row[0]) arcpy.SelectLayerByAttribute_management('input2', "", "ID = " + str(row[0])) print "Selecting the input1 features..." arcpy.SelectLayerByLocation_management("input1", "INTERSECT", "input2", "", "") print "Clipping the selected input1 features with the selected input2 feature..." arcpy.Clip_analysis("input1", "input2", r"output.gdb/input1InID" + str(row[0]), "0.001") print "Add identification field..." arcpy.AddField_management(r"output.gdb/input1InID" + str(row[0]), "ID", "LONG") print "Assign input2 ID field value to the output..." arcpy.CalculateField_management(r"output.gdb/input1InID" + str(row[0]), "ID", str(row[0]), "PYTHON_9.3") progressCounter +=1 print "Merge all the outputs..." arcpy.env.workspace = os.path.join(os.getcwd(), r"output.gdb") fcList = arcpy.ListFeatureClasses() arcpy.Merge_management(fcList, r"output.gdb/mergedFC") stopTime = time.time() print "Total time in seconds = " + str(int(stopTime-startTime)) + " and in minutes = " + str(int(stopTime-startTime)/60) print "DONE"except Exception: print "FAILED" print arcpy.GetMessages() |
You add code to transfer as many of the attributes from the second input as you want. If you want this method to go a little faster, you could play with sending the intermediate data to in_memory featureclasses. Trouble is, you’ll have to manage how many outputs you send to in_memory if your data is very large. You may use up all your memory storing the intermediate data and cause the workflow to fail.
There are other possible problems with this workflow. The main ones are SelectLayerByLocation ‘INTERSECT’ doesn’t use the exact same rules to select features as Intersect does (see here) and creating and managing all that intermediate data is painful and slow.
So, here’s a much better way to do this…
Better… Intersect geometry method
We can get rid of the creation and maintenance of all that intermediate data, use a method that mimics the Intersect tool, and make this all run tons faster on larger, more complex data.
Let’s use a geometry method instead!
Here is a simplified code snippet explaining the core basics of the workflow:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
inCursor = arcpy.da.InsertCursor(r"output.gdb/IntersectResult", fldsOutput)with arcpy.da.SearchCursor("input1", fldsInput1) as cursor: for row in cursor: # For each feature in input1 # for each feature, select the features in input2 that it intersects arcpy.SelectLayerByLocation_management("input2", "INTERSECT", row[-1]) with arcpy.da.SearchCursor("input2", fldsInput2) as cursor2: for row2 in cursor2: # for each selected feature from input2 # intersect it with the feature from input1 clippedFeature = row2[-1].intersect(row[-1], 4) # setup the insert cursor (for the input you previously created) flds2Insert[-1] = clippedFeature inCursor.insertRow(flds2Insert) # Insert the resulting geometry from using INTERSECT geometry method |
For a fully functional (I hope!) script tool and script that you can try out, download the Pairwise Intersect Tool here.
Taking a look at the same example I used above except this time I use the PairWiseIntersect tool:
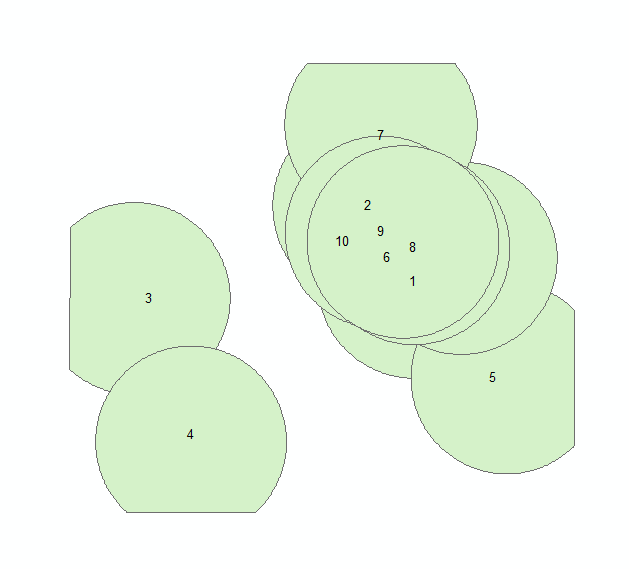
That’s more like it!
In testing we’ve done, the “Better” method is multitudes faster with large and/or complex data and it also gets through cases the Intersect Overlay tool appears to have trouble with (and for the most part these ‘trouble’ cases do not make sense to process using the Intersect tool).
Many thanks to Jason Pardy for reviewing the code and blog contents.
Commenting is not enabled for this article.